
Managing AWS Autoscaling Groups and Load Balancers using Terraform
This time I’ll be using an environment with a Load Balancer and an Autoscaling Group, which is a more complex architecture than the previous one. …

In order to pass the Terraform Associate Exam I followed the Official guide as a baseline for my studies, as I usually do for certification exams, and have been working well.
The HashiCorp Terraform Associate is considered a foundational level certification, so you can expect to have essential knowledge and skills on the concepts and not necessarily lots of hands-on practice. If you already work with Terraform you probably be able to go very quicky over the topics, but it’s important to know some details and also some commands that are not so common. You must also know the features that exist on Terraform Enterprise packages and Terraform Cloud.
Important notes about the test: it is 57 questions long and is a proctored exam. You get 60 minutes to complete and you can mark questions for later review. The certification is valid for two years. Since Terraform is quickly and constantly evolving, it makes sense that it has a shorter validity than most certifications (three years).
My personal tips for this and any other certification exam: do lots of practice tests, go over every subject at least once even if you know it already from previous experience, make notes and don’t just study for the test, apply the knowledge in labs or personal projects. I would say that practicing is at least 2x more efficient in making the knowledge permanent than reading or watching videos.
Official Exam Information from Hashicorp can be found here: HashiCorp Certified: Terraform Associate (002)
| Objective | Description |
|---|---|
| 1 | Understand Infrastructure as Code (IaC) concepts |
| 2 | Understand Terraform’s purpose (vs other IaC) |
| 3 | Understand Terraform basics |
| 4 | Use the Terraform CLI (outside of core workflow) |
| 5 | Interact with Terraform modules |
| 6 | Navigate Terraform workflow |
| 7 | Implement and maintain state |
| 8 | Read, generate, and modify configuration |
| 9 | Understand Terraform Cloud and Enterprise capabilities |
What I’m gonna do here is go over each of the objectives and cover (almost) everything required to know in order to pass the exam. Most of the content is provided by the official study guide and the exam review, so I’ll be using them as reference. It’s probably gonna be a long read, but I rather have it all in one place than making several posts on the same subject.
Infrastructure as code (IaC) tools allow you to manage infrastructure with configuration files rather than through a graphical user interface. IaC allows you to build, change, and manage your infrastructure in a safe, consistent, and repeatable way by defining resource configurations that you can version, reuse, and share.
IaC makes it easy to provision and apply infrastructure configurations by standardizing the workflow. This is accomplished by using a common syntax across a number of different infrastructure providers (e.g. AWS, GCP). Some key advantages of using IaC patterns are:
Terraform is cloud-agnostic and allows a single configuration to be used to manage multiple providers, and to even handle cross-cloud dependencies. With Terraform, users can manage a heterogeneous environment with the same workflow by creating a configuration file to fit the needs of that platform or project. Terraform plugins called providers let Terraform interact with cloud platforms and other services via their application programming interfaces (APIs). HashiCorp and the Terraform community have written over 1,000 providers to manage resources on Amazon Web Services (AWS), Azure, Google Cloud Platform (GCP), Kubernetes, Helm, GitHub, Splunk, and DataDog, just to name a few.
Terraform keeps track of your real infrastructure in a state file, which acts as a source of truth for your environment. Terraform uses the state file to determine the changes to make to your infrastructure so that it will match your configuration.
Terraform can be installed using the user’s terminal:
https://learn.hashicorp.com/tutorials/terraform/install-cli
Examples:
## Mac OS
brew install terraform
## Windows
choco install terraform
## Linux
sudo apt install terraform
There might be previous steps necessary according to your system, like installing the package manager or adding the repository.
Alternatively, Terraform can be manually installed by downloading the binary to your computer.
Terraform uses a plugin-based architecture to support hundreds of infrastructure and service providers. Initializing a configuration directory downloads and installs providers used in the configuration. Terraform plugins are compiled for a specific operating system and architecture, and any plugins in the root of the user’s plugins directory must be compiled for the current system. A provider is a plugin that Terraform uses to translate the API interactions with that platform or service.
Terraform must initialize a provider before it can be used. The initialization process downloads and installs the provider’s plugin so that it can later be executed. Terraform knows which provider(s) to download based on what is declared in the configuration files. For example:
provider "aws" {
region = "us-west-2"
}
The provider block can contain the following meta-arguments:
version - constrains which provider versions are allowed;alias - enables using the same provider with different configurations (e.g. provisioning resources in multiple AWS regions).HashiCorp recommends using provider requirements instead.
By default, a plugin is downloaded into a subdirectory of the working directory so that each working directory is self-contained. As a consequence, if there are multiple configurations that use the same provider then a separate copy of its plugin will be downloaded for each configuration. To manually install a provider, move it to:
## MacOS / Linux
~/.terraform.d/plugins
## Windows
%APPDATA%\terraform.d\plugins
Given that provider plugins can be quite large, users can optionally use a local directory as a shared plugin cache. This is enabled through using the plugin_cache_dir setting in the CLI configuration file.
plugin_cache_dir = "$HOME/.terraform.d/plugin-cache"
This configuration ensures each plugin binary is downloaded only once.
To instantiate the same provider for multiple configurations, use the alias argument. For example, the AWS provider requires specifying the region argument. The following code block demonstrates how alias can be used to provision resources across multiple regions using the same configuration files.
provider "aws" {
region = "us-east-1"
}
provider "aws" {
region = "us-west-1"
alias = "pncda"
}
resource "aws_vpc" "vpc-pncda" {
cidr_block = "10.0.0.0/16"
provider = "aws.pncda"
}
Providers are released on a separate rhythm from Terraform itself, and so each provider has its own version number. For production use, consider constraining the acceptable provider versions in the configuration to ensure that new versions with breaking changes will not be automatically installed by terraform init in future.
Any non-certified or third-party providers must be manually installed, since terraform init cannot automatically download them.
The required_version setting can be used to constrain which versions of Terraform can be used with the configuration.
terraform {
required_version = ">= 0.14.3"
}
The value for required_version is a string containing a comma-delimited list of constraints. Each constraint is an operator followed by a version number. The following operators are allowed:
| Operator | Usage | Example |
= (or no operator)
|
Use exact version | "= 0.14.3"
Must use v0.14.3 |
!=
|
Version not equal | "!=0.14.3"
Must not use v0.14.3 |
> or >= or < or <=
|
Version comparison | ">= 0.14.3"
Must use a version greater than or equal to v0.14.3 |
~>
|
Pessimistic constraint operator that both both the oldest and newest version allowed | "~>= 0.14"
Must use a version greater than or equal to v0.14 but less than v0.15 (which includes v0.14.3) |
Similarly, a provider version requirement can be specified. The following is an example limited the version of AWS provider:
provider "aws" {
region = "us-west-2"
version = ">=3.1.0"
}
It is recommended to use these operators in production to ensure the correct version is being used and avoid accidental upgrades that might have breaking changes.
Provisioners can be used to model specific actions on the local machine or on a remote machine. For example, a provisioner can enable uploading files, running shell scripts, or installing or triggering other software (e.g. configuration management) to conduct initial setup on an instance. Provisioners are defined within a resource block:
resource "aws_instance" "example" {
ami = "ami-b374d5a5"
instance_type = "t2.micro"
provisioner "local-exec" {
command = "echo hello > hello.txt"
}
}
Multiple provisioner blocks can be used to define multiple provisioning steps.
HashiCorp recommends that provisioners should only be used as a last resort.
This section will cover the various types of generic provisioners. There are also vendor specific provisioners for configuration management tools (e.g. Salt, Puppet).
The file provisioner is used to copy files or directories from the machine executing Terraform to the newly created resource.
resource "aws_instance" "web" {
# ...
provisioner "file" {
source = "conf/myapp.conf"
destination = "/etc/myapp.conf"
}
}
The file provisioner supports both ssh and winrm type connections.
local-exec
The local-exec provisioner runs by invoking a process local to the user’s machine running Terraform. This is used to do something on the machine running Terraform, not the resource provisioned. For example, a user may want to create an SSH key on the local machine.
resource "null_resource" "generate-sshkey" {
provisioner "local-exec" {
command = "yes y | ssh-keygen -b 4096 -t rsa -C 'terraform-kubernetes' -N '' -f ${var.kubernetes_controller.["private_key"]}"
}
}
remote-exec
Comparatively, remote-exec which invokes a script or process on a remote resource after it is created. For example, this may be used to bootstrap a newly provisioned cluster or to run a script.
resource "aws_instance" "example" {
key_name = aws_key_pair.example.key_name
ami = "ami-04590e7389a6e577c"
instance_type = "t2.micro"
connection {
type = "ssh"
user = "ec2-user"
private_key = file("~/.ssh/terraform")
host = self.public_ip
}
provisioner "remote-exec" {
inline = [
"sudo amazon-linux-extras enable nginx1.12",
"sudo yum -y install nginx",
"sudo systemctl start nginx"
]
}
}
Both ssh and winrm connections are supported.
By default, provisioners are executed when the defined resource is created and during updates or other parts of the lifecycle. It is intended to be used for bootstrapping a system. If a provisioner fails at creation time, the resource is marked as tainted. Terraform will plan to destroy and recreate the tainted resource at the next terraform apply command.
By default, when a provisioner fails, it will also cause the terraform apply command to fail. The on_failure parameter can be used to specify different behavior.
resource "aws_instance" "web" {
# ...
provisioner "local-exec" {
command = "echo The server's IP address is ${self.private_ip}"
on_failure = "continue"
}
}
Expressions in provisioner blocks cannot refer to the parent resource by name. Use the self object to represent the provisioner’s parent resource (see previous example).
Additionally, provisioners can also be configured to run when the defined resource is destroyed. This is configured by specifying when = “destroy” within the provisioner block.
resource "aws_instance" "web" {
# ...
provisioner "local-exec" {
when = "destroy"
command = "echo 'Destroy-time provisioner'"
}
}
By default, a provisioner only runs at creation. To run a provisioned at deletion, it must be explicitly defined.
Let’s first have an overview on all of the CLI commands available:
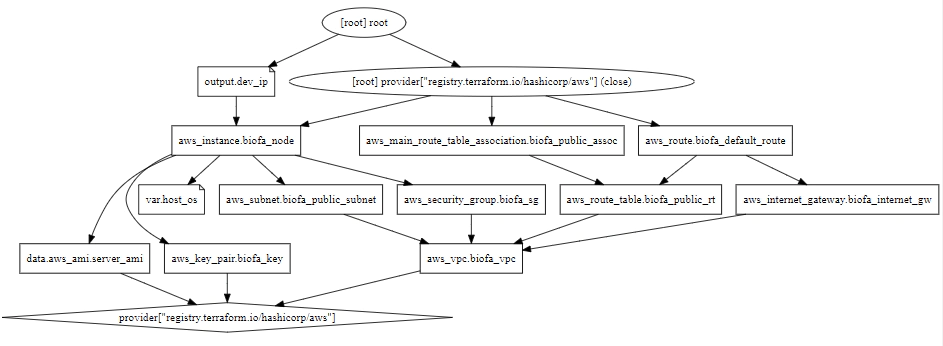
Some of the commands above are not covered in detail by the official study guide, like terraform graph for instance. This command renders the output below:
% terraform graph
digraph {
compound = "true"
newrank = "true"
subgraph "root" {
"[root] aws_instance.biofa_node (expand)" [label = "aws_instance.biofa_node", shape = "box"]
"[root] aws_internet_gateway.biofa_internet_gw (expand)" [label = "aws_internet_gateway.biofa_internet_gw", shape = "box"]
"[root] aws_key_pair.biofa_key (expand)" [label = "aws_key_pair.biofa_key", shape = "box"]
....
"[root] provider[\"registry.terraform.io/hashicorp/aws\"] (close)" -> "[root] aws_instance.biofa_node (expand)"
"[root] provider[\"registry.terraform.io/hashicorp/aws\"] (close)" -> "[root] aws_main_route_table_association.biofa_public_assoc (expand)"
"[root] provider[\"registry.terraform.io/hashicorp/aws\"] (close)" -> "[root] aws_route.biofa_default_route (expand)"
"[root] root" -> "[root] output.dev_ip"
"[root] root" -> "[root] provider[\"registry.terraform.io/hashicorp/aws\"] (close)"
}
}
The graph is presented in the DOT language. The typical program that can read this format is GraphViz, but many web services are also available to read this format, like this. here’s an example of a graphical representation of this:
Another command that is worth mentioning is terraform providers, which prints out a tree of modules in the referenced configuration annotated with their provider requirements:
% terraform providers
Providers required by configuration:
.
└── provider[registry.terraform.io/hashicorp/aws] ~> 3.0
terraform fmt to format code
The terraform fmt command is used to reformat Terraform configuration files in a canonical format and style. Using this command applies a subset of the Terraform language style conventions, along with other minor adjustments for readability. The following are common flags that may be used:
terraform fmt -diff - to output differences in formatting;terraform fmt -recursive - apply format to subdirectories;terraform fmt -list=false - when formatting many files across a number of directories, use this to not list files formatted using command.The canonical format may change between Terraform versions, so it’s a good practice to run terraform fmt after upgrading. This should be done on any modules along with other changes being made to adopt the new version.
terraform taint to taint Terraform resources
The terraform taint command manually marks a Terraform-managed resource as tainted, which marks the resource to be destroyed and recreated at the next apply command. Command usage resembles:
terraform taint [options] address
terraform taint aws_security_group.allow_all
To taint a resource inside a module:
terraform taint "module.kubernetes.aws_instance.k8_node[4]"
The address argument is the address of the resource to mark as tainted. The address is in the resource address syntax. When tainting a resource, Terraform reads from the default state file (terraform.tfstate). To specify a different path, use:
terraform taint -state=path
This command does not modify infrastructure, but does modify the state file in order to mark a resource as tainted. Once a resource is marked as tainted, the next plan will show that the resource is to be destroyed and recreated. The next apply will implement this change.
Forcing the recreation of a resource can be useful to create a certain side-effect not configurable in the attributes of a resource. For example, re-running provisioners may cause a node to have a different configuration or rebooting the machine from a base image causes new startup scripts to execute.
The terraform untaint command is used to unmark a Terraform-managed resource as tainted, restoring it as the primary instance in the state.
terraform untaint aws_security_group.allow_all
Similarly, this command does not modify infrastructure, but does modify the state file in order to unmark a resource as tainted.
This command is deprecated. For Terraform v0.15.2 and later, it is recommended using the -replace option with terraform apply instead.
Using the -replace option with terraform apply will force Terraform to replace an object even though there are no configuration changes that would require it. Example:
terraform apply -replace="aws_instance.example[0]"
terraform import to import existing infrastructure into your Terraform state
The terraform import command is used to import existing resources to be managed by Terraform. Effectively this imports existing infrastructure (created by other means) and allows Terraform to manage the resource, including destroy. The terraform import command finds the existing resource from ID and imports it into the Terraform state at the given address. Command usage resembles:
terraform import [options] address ID
terraform import aws_vpc.vpcda vpc-0a1be4pncda9
The ID is dependent on the resource type being imported. For example, for AWS instances the ID resembles i-abcd1234 whereas the zone ID for AWS Route53 resembles L69ZFG4TCUOZ1M.
Because any resource address is valid, the import command can import resources into modules as well directly into the root of state. Note that resources can be imported directly into modules.
terraform workspace to create workspaces
Workspaces are technically equivalent to renaming a state file. Each Terraform configuration has an associated backend that defines how operations are executed and where persistent data (e.g. Terraform state) is stored. This persistent data stored in the backend belongs to a workspace. A default configuration has only one workspace named default with a single Terraform state. Some backends support multiple named workspaces, allowing multiple states to be associated with a single configuration. Command usage resembles:
terraform workspace list
terraform workspace new <name>
terraform workspace show
terraform workspace select <name>
terraform workspace delete <name>
The default workspace cannot be deleted.
Workspaces can be specified within configuration code. This example uses the workspace name as a tag:
resource "aws_instance" "example" {
tags = {
Name = "web - ${terraform.workspace}"
}
# ... other arguments
}
A common use case for multiple workspaces is to create a parallel, distinct copy of a set of infrastructure in order to test a set of changes before modifying the main production infrastructure. For example, a developer working on a complex set of infrastructure changes might create a new temporary workspace in order to freely experiment with changes without affecting the default workspace.
For a local state configuration, Terraform stores the workspace states in a directory called terraform.tfstate.d.
terraform state to view Terraform state
There are cases in which the Terraform state needs to be modified. Rather than modify the state directly, the terraform state commands should be used instead.
The terraform state list command is used to list resources within the state.
The command will list all resources in the state file matching the given addresses (if any). If no addresses are given, then all resources are listed. To specify a resource:
terraform state list aws_instance.bar
The terraform state pull command is used to manually download and output the state from remote state. This command downloads the state from its current location and outputs the raw format to stdout. While this command also works with local state, it is not very useful because users can see the local file.
The terraform state mv command is used to move items in the state. It can be used for simple resource renaming, moving items to and from a module, moving entire modules, and more. Because this command can also move data to a completely new state, it can be used to refactor one configuration into multiple separately managed Terraform configurations.
terraform state mv [options] SOURCE DESTINATION
terraform state mv 'aws_instance.worker' 'aws_instance.helper'
The terraform state rm command is used to remove items from the state.
terraform state rm 'aws_instance.worker'
terraform state rm 'module.compute'
It is important to note that items removed from the Terraform state are not physically destroyed, these items are simply no longer managed by Terraform. For example, if an AWS instance is deleted from the state, the AWS instance will continue running, but terraform plan will no longer manage that instance.
Terraform has detailed logs that can be enabled by setting the TF_LOG environment variable to any value. This will cause detailed logs to appear on stderr.
Users can set TF_LOG to one of the log levels TRACE, DEBUG, INFO, WARN or ERROR to change the verbosity of the logs. TRACE is the most verbose and it is the default if TF_LOG is set to something other than a log level name.
To persist logged output users can set TF_LOG_PATH in order to force the log to always be appended to a specific file when logging is enabled. Note that even if TF_LOG_PATH is set, TF_LOG must be set in order for any logging to be enabled.
Modules can either be loaded from the local filesystem, or a remote source. Terraform supports a variety of remote sources, including the Terraform Registry, most version control systems, HTTP URLs, and Terraform Cloud or Terraform Enterprise private module registries.
The configuration that calls a module is responsible for setting the input values, which are passed as arguments in the module block. Input variables serve as parameters for a Terraform module, allowing aspects of the module to be customized without modifying the module’s code. It is common that most of the arguments to a module block will set variable values. Input variables allow modules to be shared between different configurations.
When navigating the Terraform Registry, there is an “Inputs” tab for each module that describes all of the input variables supported.
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
name = "vpc"
cidr = var.vpc_cidr
azs = var.azs
private_subnets = var.private_subnets
public_subnets = var.public_subnets
enable_nat_gateway = true
enable_vpn_gateway = true
tags = {
Terraform = "true"
Environment = var.name_env
}
}
Module outputs are typically passed to other parts of the Terraform configuration or defined as outputs in the root module. Wherein, the output values are specified as:
module.<MODULE NAME>.<OUTPUT NAME>
A resource defined in a module is encapsulated, so referencing the module cannot directly access its attributes. A child module can declare an output value to export select values to be accessible by the parent module. The contents of the outputs.tf file may contain code block(s) similar to:
output "vpc_public_subnets" {
description = "IDs of the VPC's public subnets"
value = module.vpc.public_subnets
}
The Terraform Registry is an interactive resource for discovering a wide selection of integrations (providers), configuration packages (modules), and security rules (policies) for use with Terraform. The Registry includes solutions developed by HashiCorp, third-party vendors, and the community.
The Terraform Registry is integrated directly into Terraform so you can directly specify providers and modules. Anyone can publish and consume providers, modules, and policies on the public Terraform Registry.
Each module in the registry is versioned. These versions syntactically must follow semantic versioning.
Use the version argument in the module block to specify versions:
module "consul" {
source = "hashicorp/consul/aws"
version = "0.0.5"
servers = 3
}
More information about modules can be found here.
The core Terraform workflow has three steps:
This core workflow is a loop; the next time you want to make changes, you start the process over from the beginning. More information about the Terraform Workflow can be found here.
terraform init)
The terraform init command initializes a working directory containing Terraform configuration files. The command only initializes and never deletes an existing configuration or state, therefore is safe to run the command multiple times. During init, the root configuration directory is consulted for backend configuration and the selected backend is initialized using the defined configuration settings. The following are common flags used with the terraform init command:
terraform init -upgrade - upgrade modules and pluginsterraform init -backend=false - skip backend initializationterraform init -get=false - skip child module installationterraform init -get-plugins=false - skip plugin installationterraform validate)
The terraform validate command validates the configuration files in a directory. Any remote services (i.e. remote state, provider APIs) are not validated, only the configuration files themselves. Validate runs checks to verify whether a configuration is syntactically valid and internally consistent, regardless of any provided variables or existing state. This provides a general validation of the modules, including correctness of attribute names and value types.
terraform validate requires an initialized working directory with any referenced plugins and modules installed.
terraform plan)
The terraform plan command creates an execution plan. Terraform performs a refresh, unless explicitly disabled, and then determines what actions are required to achieve the desired state defined in the configuration files. The following are common flags used with the terraform plan command:
terraform plan -out=tfplan - saves execution planterraform apply tfplan - applies execution planterraform plan -detailed-exitcode - returns a detailed exit code when the command exitsterraform plan -refresh=true - update the state prior to planterraform apply)
The terraform apply command applies the changes required for reaching the desired state of the configuration, or the predetermined set of actions generated by a terraform plan execution plan.
terraform destroy)
The terraform destroy command is used to deprovision and destroy the Terraform-managed resources.
A Terraform backend determines how the state is loaded and how operations, such as terraform apply, are executed. This abstraction enables users to store sensitive state information in a different, secured location. Backends are configured with a nested backend block within the top-level terraform block. Only one backend block can be provided in a configuration. Backend configurations cannot have any interpolations or use any variables, thus must be hardcoded.
By default, Terraform uses the local backend. The local backend stores state on the local filesystem, locks that state using the system, and performs operations locally.
terraform {
backend "local" {
path = "relative/path/to/terraform.tfstate"
}
}
You don’t need to declare a local state block unless it’s desired for the backend to be a different location than the working directory. The backend defaults to terraform.tfstate relative to the root module.
When supported by the backend type (e.g. azurerm, S3, Consul), Terraform locks the state for all operations that could write state. This prevents others from acquiring the lock and potentially corrupting the state by attempting to write changes. Locking happens automatically on all applicable operations. If state locking fails, Terraform will not continue.
State locking can be disabled for most commands using the -lock flag, however, this is not recommended. The terraform force-unlock command will manually unlock the state for the defined configuration. While this command does not modify the infrastructure resources, it does remove the lock on the state for the current configuration. Be very careful with this command, unlocking the state when another user holds the lock could cause multiple writers.
terraform force-unlock LOCK_ID [DIR]
The force-unlock command should only be used in the scenario that automatic unlocking failed. As a means of protection, the force-unlock command requires a unique LOCK_ID. Terraform will output a LOCK_ID if automatic unlocking fails.
The Consul backend also requires a Consul access token. Per the recommendation of omitting credentials from the configuration and using other mechanisms, the Consul token would be provided by setting either the CONSUL_HTTP_TOKEN or CONSUL_HTTP_AUTH environment variables. See the documentation of your chosen backend to learn how to provide credentials to it outside of its main configuration.
With remote state, Terraform writes the state data to a remote data store, which can then be shared between all members of a team. Terraform supports storing state in Terraform Cloud, HashiCorp Consul, Amazon S3, Azure Blob Storage, Google Cloud Storage, Alibaba Cloud OSS, and more.
Remote state is implemented by a backend or by Terraform Cloud, both of which you can configure in your configuration’s root module.
The terraform refresh command is used to reconcile the state Terraform knows about (via its state file) with the real-world infrastructure. This can be used to detect any drift from the last-known state or to update the state file. While this command does not change the infrastructure, the state file is modified. This could cause changes to occur during the next plan or apply due to the modified state.
This does not modify infrastructure, but does modify the state file. If the state is changed, this may cause changes to occur during the next plan or apply.
This command is deprecated, because its default behavior is unsafe if you have misconfigured credentials for any of your providers.
Instead of using refresh, you should use terraform apply -refresh-only. This alternative command will present an interactive prompt for you to confirm the detected changes. Wherever possible, avoid using terraform refresh explicitly and instead rely on Terraform’s behavior of automatically refreshing existing objects as part of creating a normal plan.
An example of a backend configuration would be:
terraform {
backend "s3" {
bucket = "bachelol-bucket-tfstate"
key = "dev/terraform.tfstate"
region = "us-east-1"
}
}
If a local state is then changed to an S3 backend, users will be prompted whether to copy existing state to the new backend when terraform init is executed. Similarly, if a remote backend configuration is removed, users will be prompted to migrate state back to local when terraform init is executed.
When some or all of the arguments are omitted, it is called a partial configuration. Users do not have to specify every argument for the backend configuration. In some cases, omitting certain arguments may be desirable, such as to avoid storing secrets like access keys, within the main configuration. To provide the remaining arguments, users can do this using one of the following methods:
init command line. To specify a file, use the -backend-config=PATH option when running terraform init. If the file contains secrets it may be kept in a secure data store, such as Vault, in which case it must be downloaded to the local disk before running Terraform.init command line. Note that many shells retain command-line flags in a history file, so this isn’t recommended for secrets. To specify a single key/value pair, use the -backend-config="KEY=VALUE" option when running terraform init.When using partial configuration, it is required to specify an empty backend configuration in a Terraform configuration file. This specifies the backend type, such as:
terraform {
backend "consul" {}
}
An example of passing partial configuration with command-line key/value pairs:
$ terraform init \
-backend-config="address=demo.consul.io" \
-backend-config="path=example_app/terraform_state" \
-backend-config="scheme=https"
However, this is not recommended for secrets because many shells retain command-line flags in the history.
When using local state, state is stored in plain-text JSON files.
When using remote state, state is only ever held in memory when used by Terraform. It may be encrypted at rest, but this depends on the specific remote state backend.
Terraform Cloud always encrypts state at rest and protects it with TLS in transit. Terraform Cloud also knows the identity of the user requesting state and maintains a history of state changes. This can be used to control access and track activity. Terraform Enterprise also supports detailed audit logging.
The S3 backend supports encryption at rest when the encrypt option is enabled. IAM policies and logging can be used to identify any invalid access. Requests for the state go over a TLS connection.
Input variables are a means to parameterize Terraform configurations. This is particularly useful for abstracting away sensitive values. These are defined using the variable block type:
variable "region" {
default = "sa-east-1"
}
To then reference and use this variable, the resulting syntax would be var.region:
provider "aws" {
region = var.region
}
There are three ways to assign configuration variables:
terraform apply -var 'region=sa-east-1';terraform.tfvars with the variable assignments; different files can be created for different environments (e.g. dev or prod);TF_VAR_name to find the variable value. For example, the TF_VAR_region variable can be set in the shell to set the Terraform variable for a region. Environment variables can only populate string-type variables; list and map type variables must be populated using another mechanism;terraform apply is executed with any variable unspecified, Terraform prompts users to input the values interactively; while these values are not saved, it does provide a convenient workflow when getting started.Strings and numbers are the most commonly used variables, but lists (arrays) and maps (hashtables or dictionaries) can also be used. Lists are defined either explicitly or implicitly. Example:
## Declare implicitly by using brackets []
variable "cidrs" {
default = []
}
## Declare explicitly with 'list'
variable "cidrs" {
type = list
}
## Specify list values in terraform.tfvars file
cidrs = [ "10.0.0.0/16", "10.1.0.0/16" ]
A map is a key/value data structure that can contain other keys and values. Maps are a way to create variables that are lookup tables. Example:
## Declare variables
variable "region" {}
variable "amis" {
type = "map"
default = {
"us-east-1" = "ami-b374d5a5"
"us-west-2" = "ami-fc0b939c"
}
}
## Reference variables
resource "aws_instance" "example" {
ami = var.amis[var.region]
instance_type = "t2.micro"
}
The above mechanisms for setting variables can be used together in any combination. If the same variable is assigned multiple values, Terraform uses the last value it finds, overriding any previous values. Terraform loads variables in the following order, with later sources taking precedence over earlier ones:
terraform.tfvars file, if present;terraform.tfvars.json file, if present;*.auto.tfvars or *.auto.tfvars.json files, processed in lexical order of their filenames;-var and -var-file options on the command line, in the order provided (this includes variables set by a Terraform Cloud workspace).The same variable cannot be assigned multiple values within a single source.
An output variable is a way to organize data to be easily queried and shown back to the Terraform user. Outputs are a way to tell Terraform what data is important and should be referenceable. This data is output when apply is called and can be queried using the terraform output command.
## Define Resources
resource "aws_instance" "importugues" {
ami = "ami-08d70e59c07c61a3a"
instance_type = "t2.micro"
}
resource "aws_eip" "ip" {
vpc = true
instance = aws_instance.importugues.id
}
## Define Output
output "ip" {
value = aws_eip.ip.public_ip
}
The example specifies to output the public_ip attribute. Run terraform apply to populate the output. The output can also be viewed by using the terraform output ip command, with ip in this example referencing the defined output.
Some providers, such as AWS, allow users to store credentials in a separate configuration file. It is a good practice in these instances to store credential keys in a config file such as .aws/credentials and not in the Terraform code.
Vault is a secrets management system that allows users to secure, store and tightly control access to tokens, passwords, certificates, encryption keys for protecting secrets and other sensitive data using a UI, CLI, or HTTP API.
It is recommended that the terraform.tfstate or .auto.tfvars files should be ignored by Git when committing code to a repository. The terraform.tfvars file may contain sensitive data, such as passwords or IP addresses of an environment that should not be shared with others.
A complex type groups multiple values into a single value. There are two categories of complex types:
list(...) - a sequence of values identified by consecutive whole numbers starting with zero;map(...) - a collection of values where each is identified by a string label;set(...) - a collection of unique values that do not have any secondary identifiers or ordering.object(...) - a collection of named attributes that each have their own type;tuple(...) - a sequence of elements identified by consecutive whole numbers starting with zero, where each element has its own type.Resources are the most important element in the Terraform language. Each resource block describes one or more infrastructure objects, such as virtual networks, compute instances, or higher-level components such as DNS records. Example:
resource "aws_instance" "web" {
ami = "ami-a1b2c3d4"
instance_type = "t2.micro"
}
A resource block declares a resource of a given type ("aws_instance") with a given local name ("web"). The name is used to refer to this resource from elsewhere in the same Terraform module.
Special arguments that can be used with every resource type, including depends_on, count, for_each, provider, and lifecycle:
depends_on: used to handle hidden resource or module dependencies that Terraform cannot automatically infer;count: creates that many instances of the resource or module. Each instance has a distinct infrastructure object associated with it, and each is separately created, updated, or destroyed when the configuration is applied;for_each: If a resource or module block includes a for_each argument whose value is a map or a set of strings, Terraform will create one instance for each member of that map or set;provider: specifies which provider configuration to use for a resource, overriding Terraform’s default behavior of selecting one based on the resource type name;lifecycle: the arguments available within a lifecycle block are create_before_destroy, prevent_destroy, ignore_changes, and replace_triggered_by.Examples:
depends_on:
resource "aws_iam_role" "example" {
name = "example"
# assume_role_policy is omitted for brevity in this example. Refer to the
# documentation for aws_iam_role for a complete example.
assume_role_policy = "..."
}
resource "aws_iam_instance_profile" "example" {
role = aws_iam_role.example.name
}
resource "aws_iam_role_policy" "example" {
name = "example"
role = aws_iam_role.example.name
policy = jsonencode({
"Statement" = [{
"Action" = "s3:*",
"Effect" = "Allow",
}],
})
}
resource "aws_instance" "example" {
ami = "ami-a1b2c3d4"
instance_type = "t2.micro"
depends_on = [
aws_iam_role_policy.example
]
}
count:
resource "aws_instance" "server" {
count = 4 # create four similar EC2 instances
ami = "ami-a1b2c3d4"
instance_type = "t2.micro"
tags = {
Name = "Server ${count.index}"
}
}
for_each:
resource "aws_iam_user" "the-accounts" {
for_each = toset( ["Todd", "James", "Alice", "Dottie"] )
name = each.key
}
provider:
# default configuration
provider "google" {
region = "us-central1"
}
# alternate configuration, whose alias is "europe"
provider "google" {
alias = "europe"
region = "europe-west1"
}
resource "google_compute_instance" "example" {
# This "provider" meta-argument selects the google provider
# configuration whose alias is "europe", rather than the
# default configuration.
provider = google.europe
# ...
}
lifecycle:
resource "azurerm_resource_group" "example" {
# ...
lifecycle {
create_before_destroy = true
}
}
Data Sources are the way for Terraform to query a platform (e.g. AWS) and retrieve data (e.g. API request to get information). The use of data sources enables Terraform configuration to make use of information defined outside of this Terraform configuration. A provider determines what data sources are available alongside its set of resource types.
data "aws_ami" "example" {
most_recent = true
owners = ["self"]
tags = {
Name = "app-server"
Tested = "true"
}
}
A data block lets Terraform read data from a given data source type (aws_ami) and export the result under the given local name (example). Data source attributes are interpolated with the syntax data.TYPE.NAME.ATTRIBUTE. To reference the data source example above, use data.aws_ami.example.id.
A Resource Address is a string that references a specific resource in a larger infrastructure. An address is made up of two parts:
[module path][resource spec]
A resource spec addresses a specific resource in the config. It takes the form of:
resource_type.resource_name[resource index]
In which these constructs are defined as:
resource_type - type of the resource being addressedresource_name - user-defined name of the resourceresource index] - an optional index into a resource with multiple instances, surrounded by square braces [ and ].For full reference to values, see here.
The Terraform language includes a number of built-in functions that you can call from within expressions to transform and combine values. The general syntax for function calls is a function name followed by comma-separated arguments in parentheses:
max(5, 12, 9)
The following is a non-exhaustive list of built-in functions:
filebase64(path) - reads the contents of a file at the given path and returns as a base64-encoded string;formatdate(spec, timestamp) - converts a timestamp into a different time format;jsonencode({"hello"="world"}) - encodes a given value to a string using JSON syntax;cidrhost("10.12.127.0/20", 16) - calculates a full host IP address for a given host number within a given IP network address prefix;file - reads the contents of a file and returns as a string;flatten - takes a list and replaces any elements that are list with a flattened sequence of the list contents;lookup - retrieves the value of a single element from a map, given its key. If the given key does not exist, the given default value is returned instead.The Terraform language does not support user-defined functions, therefore only the built-in functions are available for use.
Some resource types include repeatable nested blocks in their arguments. Users can dynamically construct repeatable nested blocks like setting using a special dynamic block type, which is supported inside resource, data, provider, and provisioner blocks:
resource "aws_elastic_beanstalk_environment" "bean" {
name = "tf-beanstalk"
application = "${aws_elastic_beanstalk_application.tftest.name}"
solution_stack_name = "64bit Amazon Linux 2018.03 v2.11.4 running Go 1.12.6"
dynamic "setting" {
for_each = var.settings
content {
namespace = setting.value["namespace"]
name = setting.value["name"]
value = setting.value["value"]
}
}
}
A dynamic block acts similar to a for expression, but instead produces nested blocks rather than a complex typed value. It iterates over a given complex value, and generates a nested block for each element of that complex value.
Sentinel is a policy as code framework that enables the same practices to be applied to enforcing and managing policy as used for infrastructure. These policies fall into a few categories:
Sentinel has been integrated into Terraform Enterprise.
The Module Registry gives Terraform users easy access to templates for setting up and running infrastructure with verified and community modules.
Terraform Cloud’s private module registry helps users share Terraform modules across an organization. It includes support for module versioning, a searchable and filterable list of available modules, and a configuration designer to help users build new workspaces faster.
By design, the private module registry works similarly to the public registry.
Using Terraform CLI, it is the working directory used to manage collections of resources. But, this is where Terraform Cloud differs: workspaces are used to collect and organize infrastructure instead of directories. A workspace contains everything Terraform needs to manage a given collection of infrastructure, and separate workspaces function like completely separate working directories.
Terraform Cloud and Terraform CLI both have features called workspaces, but the features are slightly different. CLI workspaces are alternate state files in the same working directory; a convenience feature for using one configuration to manage multiple similar groups of resources.
| Feature | OSS | Terraform Cloud | Enterprise |
| Terraform Configuration | Local or version control repo | Version control repo or periodically updated via CLI/API | Same as Terraform Cloud, but also has the following features:
|
| Variable Values | As .tfvars file, as CLI arguments, or in shell environment | In workspace | |
| State | On disk or in remote backend | In workspace | |
| Credential and Secrets | In shell environments or prompted | In workspace, stored as sensitive variables |
Terraform Cloud is an application that helps teams use Terraform together. It manages Terraform runs in a consistent and reliable environment, and includes easy access to shared state and secret data, access controls for approving changes to infrastructure, a private registry for sharing Terraform modules, detailed policy controls for governing the contents of Terraform configurations, and more.
Terraform Cloud is available as a hosted service at https://app.terraform.io. Small teams can sign up for free to connect Terraform to version control, share variables, run Terraform in a stable remote environment, and securely store remote state. Paid tiers allow you to add more than five users, create teams with different levels of permissions, enforce policies before creating infrastructure, and collaborate more effectively.
The Business tier allows large organizations to scale to multiple concurrent runs, create infrastructure in private environments, manage user access with SSO, and automates self-service provisioning for infrastructure end users.
Expressions are used to refer to or compute values within a configuration. The Terraform language allows complex expressions such as references to data exported by resources, arithmetic, conditional evaluation, and a number of built-in functions. It is important to understand an know how to use them not only for the test but for the most varied applications when using Terraform. Each expression is well documented on the official Terraform page, so i’ll link them below instead of writing about them here. Here’s a list of expressions and the link to the official page describing the features of each of Terraform’s expression syntax:
<CONDITION> ? <TRUE VAL> : <FALSE VAL> expression, which chooses between two values based on a bool condition;[for s in var.list : upper(s)], which can transform a complex type value into another complex type value;var.list[*].id, which can extract simpler collections from more complicated expressions;
This time I’ll be using an environment with a Load Balancer and an Autoscaling Group, which is a more complex architecture than the previous one. …

It’s good to have a basic terraform code that deploys a basic environment on AWS whenever you need to run some quick tests on a free tier …