This blog post documents my journey of revisiting fundamental computer science concepts and sharpening my Python coding skills. After reviewing the classics, I wrote a script to analyze and compare the performance of common sorting algorithms, including QuickSort, MergeSort, SelectionSort, and InsertionSort. Here’s an account of the analysis, the code, and the insights gained.
Background and Approach
This analysis builds upon a script initially developed during the MITx course “Introduction to Computer Science and Programming Using Python,” even incorporating the old post about learning to use decorators. I have since refined the script to remove BubbleSort in favor of InsertionSort, improved code documentation through inline comments and PEP 257-compliant docstrings, and incorporated feedback from a Grok review, including the implementation of randomized pivots in QuickSort to improve its average-case performance.
The aim of the script is to sort lists of 5000 random integers (0 to 4999). I wanted to get a better sense of how they performed, so each algorithm is timed using a decorator. It outputs the time for each run of a list copy and gives a graph at the end.
Before choosing a sorting algorithm, it’s essential to understand how the data is structured. Real-world data often falls into one of several common categories: Random, Nearly Sorted, Reversed, or Few Unique. The choice of sorting algorithm can significantly impact performance depending on the data’s characteristics. For example:
- Random: A list of customer IDs in a database, where the order is arbitrary.
- Nearly Sorted: A log file where entries are mostly in chronological order but occasionally have timestamps slightly out of sequence.
- Reversed: A list of scores in a competition sorted from highest to lowest.
- Few Unique: A list of product ratings (1-5 stars), where the number of distinct values is limited.
This consideration is crucial when working with large datasets, where even a small improvement in efficiency (e.g., 10%) can lead to significant savings.
The timing decorator is implemented using time() from the time library:
| |
This code defines a timing decorator that runs a start and end timer for a function to determine runtime and measure performance. The result is then stored.
Quick Sort: Figuring Out the Pivot
I’ve read that Quick Sort is one of the most popular sorting algorithms because it’s efficient on average. Quick Sort is based on a concept called divide and conquer. It works by recursively partitioning the list around a chosen element, called the pivot. All elements smaller than the pivot are moved to its left, and all elements larger than the pivot are moved to its right. This process is repeated recursively for the left and right partitions until the entire list is sorted.
A good choice of pivot is crucial. If a bad pivot is chosen, like always picking the smallest or largest element, Quick Sort can degrade to O(n²). That’s why picking a good pivot, such as using the middle element or a randomized pivot, is crucial. One technique to pick a good pivot is to use “median of three”, where we pick the first, middle, and last item, and choose the median of these values. In the worst-case scenario, such as a reversed list and always picking the first element as the pivot, the algorithm makes many comparisons, O(n^2). But if everything is chosen to be perfect, the scenario makes only N log N comparisons
The first time I used Quick Sort I picked the first element as a pivot, which might not be ideal. This time I changed it to pick it randomly, as suggested during a review using Grok.
Despite this worst-case scenario, quickSort is often faster in practice than mergeSort because it doesn’t require extra memory for merging. That’s why it is commonly used in real-world applications, including in many programming languages’ built-in sorting functions. Depending on the size of the list, memory can become an important factor.
Merge Sort: Divide, Conquer, and Combine
Like Quick Sort, Merge Sort employs a divide-and-conquer strategy to sort a list. Instead of sorting the entire list at once, it breaks the list down into smaller, more manageable sublists, sorts them individually, and then merges these sorted sublists back together in a controlled manner.
Here’s a breakdown of the process:
Divide: The list is recursively divided into two halves until you’re left with sublists containing only single elements. Consider the list [5, 2, 4, 6, 1, 3]. It’s divided into [5, 2, 4] and [6, 1, 3], then further into [5], [2, 4], [6], [1, 3], and finally, [5], [2], [4], [6], [1], [3].
Conquer: Each single-element sublist is inherently sorted (a list of one element is always sorted).
Merge: The magic happens during the merging step. The sublists are merged back together in sorted order. For instance, [5] and [2] merge into [2, 5], then [2, 5] and [4] merge into [2, 4, 5]. This continues until the full list is rebuilt, resulting in [1, 2, 3, 4, 5, 6]. The merging is efficient because we’re always combining already sorted sublists, which allows for a linear-time (O(n)) merging process.
Merge Sort has a time complexity of O(n log n) in all cases (best, average, worst), making it a reliable choice when consistent performance is crucial. However, this efficiency comes at a cost: Merge Sort requires additional memory space to store the temporary sublists during the merging process, making it a bit less space-efficient than algorithms like quickSort or insertionSort (in their in-place implementations).
Selection Sort: Repeated Minimum Finding
Selection Sort offers a straightforward, albeit inefficient, approach to sorting. It works by repeatedly finding the smallest element in the unsorted portion of the list and swapping it with the element at the beginning of the unsorted portion. While coding Selection Sort is relatively simple, its performance, with a time complexity of O(n²), is significantly slower than more advanced algorithms, especially for larger datasets.
Consider the list [5, 2, 4, 6, 1, 3]. Selection Sort would:
- Find the smallest element (1) and swap it with the first element (5): [1, 2, 4, 6, 5, 3]
- Find the smallest element in the remaining unsorted portion (2) (skipping already sorted ones) and swap it with the second element: [1, 2, 4, 6, 5, 3]
- Continue this process, repeatedly finding the minimum and swapping it into its correct position.
The primary disadvantage of Selection Sort is its inefficiency. It always performs a complete scan of the unsorted portion of the list, regardless of whether the list is already partially sorted or not. Also, if you have a situation where reading and writing operations are very costly (for example, if elements are stored on slow hard drives or the network), the many swaps that are involved can affect performance.
Insertion Sort: Sorting Like Playing Cards
Insertion Sort is another relatively simple sorting algorithm. One way to think about it is imagining how you sort playing cards in your hand: As you’re dealt a new card, you look at the cards you already have and insert the new card into its correct position by shifting the other cards over if needed.
The algorithm works as follows:
- Start with the second element in the list.
- Compare it with the element to its left. If the element is smaller, swap them.
- Keep moving backward, comparing and swapping until you find the correct position for the current element.
- Move on to the next element and repeat the process.
- By the time you reach the last element, the entire list is sorted.
To illustrate, consider the list [5, 2, 4, 6, 1, 3]:
- i=1, current=2. Compare 2 with 5. Swap: [2, 5, 4, 6, 1, 3]
- i=2, current=4. Compare 4 with 5. Swap: [2, 4, 5, 6, 1, 3]
- i=3, current=6. Nothing to swap.
- i=4, current=1. Compare 1 with 6, 5, 4, 2. Swap till front: [1, 2, 4, 5, 6, 3]
- i=5, current =3 Compare 3 with 6, 5, 4, 2, 1, and stop at [1, 2, 3, 4, 5, 6]
While Insertion Sort is easy to understand and implement, its time complexity is O(n²) in the worst case (e.g., a reversed list), making it slow for large, unsorted datasets. However, Insertion Sort shines when dealing with small lists or lists that are nearly sorted. In these scenarios, it can be surprisingly efficient and may even outperform more complex algorithms like QuickSort or MergeSort. The is because it is an adaptive sort where its performance depends on the nature of the already sorted data, versus the nonadaptive methods (such as mergeSort and selectionSort) where the method will run until the data is sorted.
Methodology: Analyzing Sorting Performance
To conduct the analysis, the program follows these steps:
- Data Generation: Four lists, each representing one of the scenarios described above, are generated. The list size is set to 1000. We did this in order to not reach maximum recursion limits of the sorting methods.
- Sorting and Timing: For each scenario, each sorting algorithm is applied to a copy of the generated list. This ensures that each algorithm operates on the same initial data and that previous sorting operations do not influence subsequent timing results.
- Execution Time Measurement: A
timingdecorator is used to measure the execution time of each sorting operation in milliseconds. - Visualization: The collected timing results are then used to generate a bar chart using the
matplotliblibrary. This chart provides a visual comparison of the performance of the sorting algorithms for each scenario, allowing for easy identification of their relative strengths and weaknesses.
Results
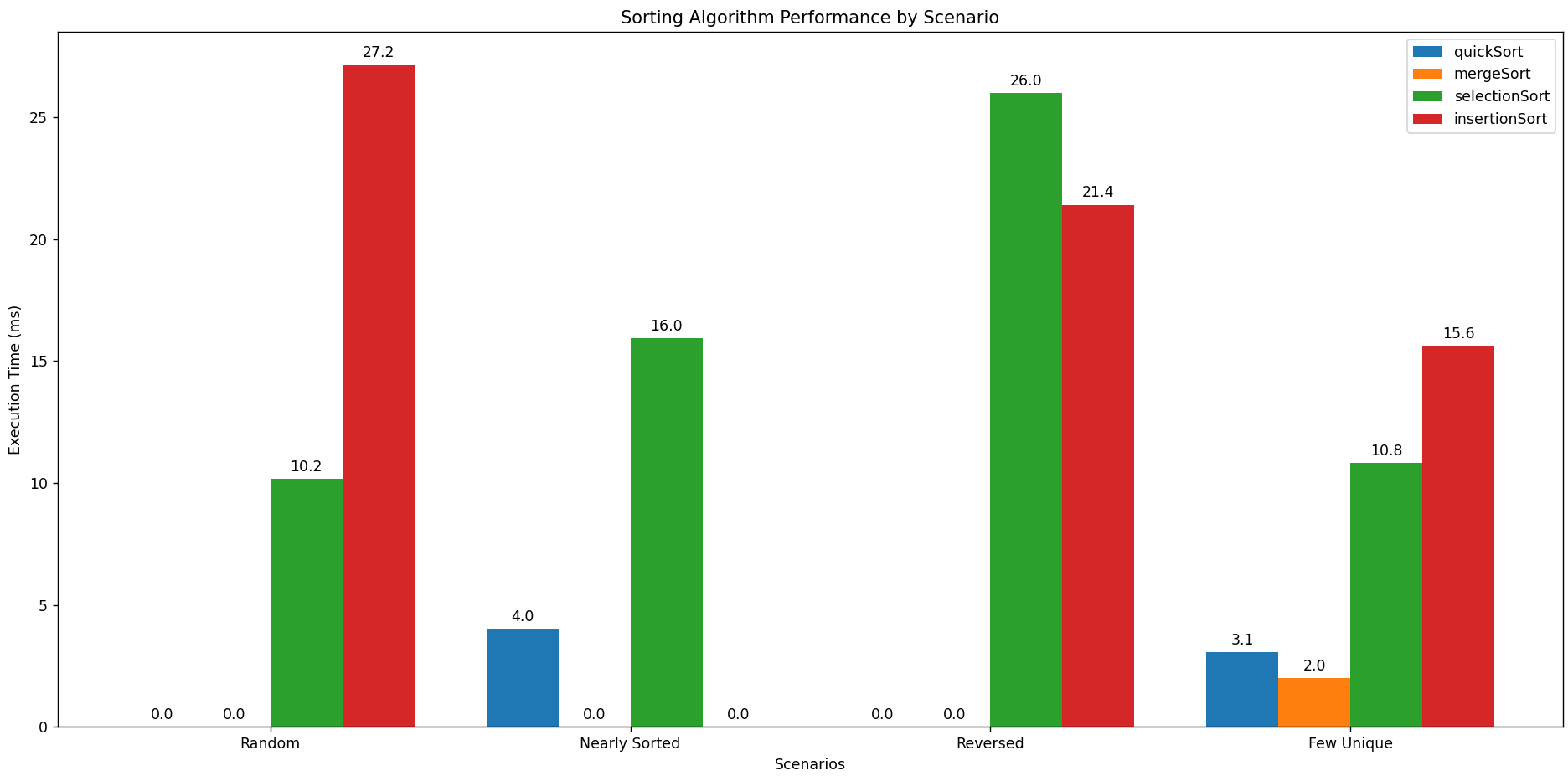
The following results were obtained on my machine using lists of 5000 integers. Remember that performance can vary depending on hardware and specific data characteristics.
Thoughts
The key observations from this analysis are:
- QuickSort: Demonstrated the best overall performance, consistently exhibiting the fastest execution times across most scenarios. The iterative implementation and randomized pivot selection likely contributed to its efficiency.
- MergeSort: Performed reasonably well, consistently with the other scenarios. Due to linear-time process, it’s more costly to do it and becomes less fast.
- SelectionSort: Significantly slower than the O(n log n) algorithms, highlighting the practical limitations of its O(n²) time complexity.
- InsertionSort: Showed competitive performance when compared to Selection Sort.
Discussion and Next Steps
This analysis provided a valuable reminder of the performance trade-offs inherent in different sorting algorithms. The results clearly illustrate the advantages of O(n log n) algorithms (QuickSort and MergeSort) for larger datasets compared to O(n²) algorithms (SelectionSort and InsertionSort).
While these findings provide a general overview, several avenues remain for further exploration:
- Larger Datasets: Running the analysis with significantly larger list sizes (e.g., 10,000, 50,000, 100,000) would further emphasize the scaling behavior of the algorithms.
- Varying Data Characteristics: Experimenting with different data distributions (e.g., different levels of “nearly sorted,” varying the number of unique values) could reveal subtle performance nuances.
- Implement
standardSortPython can call this function to provide another time measurement. - Compare the Algorithms in Various Scenarios: Talk about the advantages and the disadvantages from each algorithm in every scenario from the graph.
Full Code (Click to Show/Hide)
| |