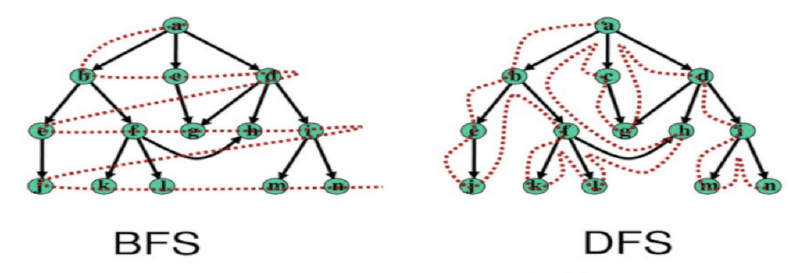
Busca em Largura (BFS)
A Busca em Largura (BFS, do inglês Breadth-First Search) é um algoritmo fundamental de busca e travessia de grafos. Ele explora sistematicamente um grafo nível por nível, começando de um nó inicial designado. Imagine explorar um labirinto: o BFS exploraria todos os caminhos a um passo da entrada, depois todos os caminhos a dois passos, e assim por diante, garantindo que o caminho mais curto seja encontrado primeiro.
Como o BFS Funciona
Inicialização:
- Comece com uma estrutura de dados fila (queue), tipicamente implementada usando
collections.dequeem Python para operações FIFO (First-In, First-Out, Primeiro a Entrar, Primeiro a Sair) eficientes. A fila inicialmente contém apenas o nó inicial. - Mantenha um conjunto (set) ou lista
visitadospara controlar os nós que já foram explorados, evitando ciclos. - Opcionalmente, um dicionário
pai(parent) é usado para armazenar o predecessor de cada nó visitado, permitindo a reconstrução do caminho mais tarde.
- Comece com uma estrutura de dados fila (queue), tipicamente implementada usando
Iteração:
- Enquanto a fila não estiver vazia:
- Remova um nó da frente da fila (dequeue). Este é o nó sendo explorado atualmente.
- Para cada vizinho do nó atual:
- Se o vizinho não foi visitado:
- Marque o vizinho como visitado.
- Adicione o vizinho ao final da fila (enqueue).
- Registre o nó atual como o pai do vizinho (se a reconstrução do caminho for necessária).
- Se o vizinho não foi visitado:
- Enquanto a fila não estiver vazia:
Terminação:
- O algoritmo termina quando a fila está vazia, indicando que todos os nós alcançáveis a partir do nó inicial foram explorados.
- Se um nó alvo for especificado, a busca pode terminar assim que o nó alvo for removido da fila. O dicionário
paipode então ser usado para reconstruir o caminho mais curto do nó inicial ao nó alvo.
Prós do BFS
- Completude: O BFS é completo, o que significa que se um caminho existe entre o nó inicial e o nó alvo, o BFS irá encontrá-lo.
- Optimalidade: O BFS garante encontrar o caminho mais curto (em termos do número de arestas) entre o nó inicial e o nó alvo em um grafo não ponderado.
- Simplicidade: O algoritmo é relativamente simples de entender e implementar.
Contras do BFS
- Consumo de Memória: O BFS pode consumir uma quantidade significativa de memória, especialmente para grafos grandes. Isso ocorre porque ele armazena todos os nós no nível atual na fila. No pior cenário, onde todo o grafo precisa ser percorrido, a fila pode crescer e conter uma grande fração do número total de nós.
- Não Adequado para Grafos Ponderados: O BFS é projetado para grafos não ponderados. Ele encontra o caminho mais curto com base no número de arestas, não no peso total das arestas. Para grafos ponderados, algoritmos como o algoritmo de Dijkstra são mais apropriados.
Onde o BFS se Destaca
- Encontrar Caminhos Mais Curtos (Grafos Não Ponderados): Sua principal força é encontrar o caminho mais curto em grafos onde todas as arestas têm o mesmo peso (ou nenhum peso).
- Teste de Conectividade: Determinar se dois nós estão conectados em um grafo.
- Web Crawlers (Robôs de Busca): O BFS pode ser usado para rastrear páginas da web, explorando links nível por nível.
- Análise de Redes Sociais: Encontrar a cadeia mais curta de conexões entre duas pessoas em uma rede social.
- Navegação GPS: Em cenários onde minimizar o número de “saltos” (hops) é mais importante do que a distância total (por exemplo, minimizar o número de transferências no transporte público).
Onde o BFS Falha
- Grafos Ponderados: Conforme mencionado anteriormente, o BFS não é adequado para encontrar o caminho mais curto em grafos onde as arestas têm pesos diferentes.
- Grafos Muito Grandes: Os requisitos de memória do BFS podem se tornar proibitivos para grafos muito grandes.
- Grafos com Altos Fatores de Ramificação (Branching Factors): Grafos onde cada nó tem muitos vizinhos podem levar a uma fila grande e alto consumo de memória.
Casos de Uso Comuns
- Pathfinding em Jogos (Busca de Caminho): Encontrar o caminho mais curto para um personagem se mover em um ambiente de jogo (onde todos os movimentos têm o mesmo custo).
- Roteamento de Rede: Descobrir a topologia da rede e encontrar os caminhos mais curtos entre dispositivos.
- Coleta de Lixo (Garbage Collection): Rastrear objetos alcançáveis na memória para identificar aqueles que podem ser desalocados com segurança.
- Redes Peer-to-Peer: Encontrar os pares mais próximos em uma rede peer-to-peer.
Busca em Profundidade (DFS)
A Busca em Profundidade (DFS, do inglês Depth-First Search) é outro algoritmo fundamental de busca e travessia de grafos. Em vez de explorar um grafo nível por nível como o BFS, o DFS explora o mais profundamente possível ao longo de cada ramo antes de retroceder (backtracking). O DFS escolherá um caminho e o seguirá até o final, então retrocederá ao último ponto de ramificação e tentará um caminho diferente.
Como o DFS Funciona
Inicialização:
- Comece com uma estrutura de dados pilha (stack), tipicamente implementada usando uma lista em Python. A pilha inicialmente contém apenas o nó inicial.
- Mantenha um conjunto (set) ou lista
visitadospara controlar os nós que já foram explorados, evitando ciclos. - Opcionalmente, um dicionário
pai(parent) é usado para armazenar o predecessor de cada nó visitado, permitindo a reconstrução do caminho mais tarde.
Iteração:
- Enquanto a pilha não estiver vazia:
- Remova um nó do topo da pilha (pop). Este é o nó sendo explorado atualmente.
- Se o nó não foi visitado:
- Marque o nó como visitado.
- Para cada vizinho do nó atual:
- Se o vizinho não foi visitado:
- Adicione o vizinho ao topo da pilha (push).
- Registre o nó atual como o pai do vizinho (se a reconstrução do caminho for necessária).
- Se o vizinho não foi visitado:
- Enquanto a pilha não estiver vazia:
Terminação:
- O algoritmo termina quando a pilha está vazia, indicando que todos os nós alcançáveis a partir do nó inicial foram explorados.
- Se um nó alvo for especificado, a busca pode terminar assim que o nó alvo for removido da pilha e for encontrado. O dicionário
paipode então ser usado para reconstruir um caminho (não necessariamente o mais curto) do nó inicial ao nó alvo.
Prós do DFS
- Eficiência de Memória: O DFS geralmente requer menos memória do que o BFS, especialmente para grafos profundos. Ele só precisa armazenar os nós no caminho atual sendo explorado, em vez de todos os nós no nível atual (como o BFS faz).
- Implementação Simples: O DFS pode ser implementado recursivamente, tornando o código muito conciso (embora a versão iterativa, usando uma pilha, também seja direta).
- Bom para Encontrar Qualquer Caminho: Se você só precisa encontrar um caminho entre dois nós (não necessariamente o mais curto), o DFS pode ser mais rápido do que o BFS.
Contras do DFS
- Não Garante Encontrar o Caminho Mais Curto: O DFS não garante encontrar o caminho mais curto. Ele encontra um caminho, mas esse caminho pode ser muito mais longo do que o caminho mais curto.
- Pode Ficar Preso em Loops Infinitos: Se o grafo contém ciclos e o conjunto
visitadosnão for usado corretamente, o DFS pode ficar preso em um loop infinito, explorando os mesmos nós repetidamente. - Pode Explorar Caminhos Irrelevantes: O DFS pode explorar caminhos que estão longe do nó alvo antes de encontrar o alvo.
Onde o DFS se Destaca
- Detecção de Ciclos: O DFS é adequado para detectar ciclos em um grafo. Se, durante a travessia, você encontrar um nó que já foi visitado (e ainda está na pilha), isso indica a presença de um ciclo.
- Ordenação Topológica: O DFS é usado em algoritmos para ordenação topológica de grafos acíclicos dirigidos (DAGs).
- Verificação da Existência de Caminho: Determinar se um caminho existe entre dois nós, mesmo que o caminho mais curto não seja necessário.
- Resolvendo Quebra-Cabeças: O DFS pode ser usado para explorar possíveis soluções em quebra-cabeças e jogos (por exemplo, resolver um labirinto, encontrar uma solução para um quebra-cabeça Sudoku).
Onde o DFS Falha
- Encontrar Caminhos Mais Curtos: Quando o caminho mais curto é necessário, o BFS ou outros algoritmos como o algoritmo de Dijkstra são melhores opções.
- Grafos com Caminhos Longos: Em grafos com caminhos muito longos, o DFS pode levar muito tempo para encontrar o nó alvo ou explorar todo o grafo.
- Grafos Infinitos: O DFS pode se perder em grafos infinitos se não houver uma condição de terminação clara.
Casos de Uso Comuns
- Detecção de Ciclos: Conforme mencionado anteriormente, o DFS é comumente usado para detectar ciclos em grafos.
- Ordenação Topológica: Ordenar tarefas em um projeto com base em dependências.
- Resolvendo Labirintos: Encontrar um caminho da entrada para a saída.
- Algoritmos de Backtracking: Resolver problemas onde você precisa explorar diferentes possibilidades e retroceder quando um beco sem saída é atingido (por exemplo, resolver problemas de satisfação de restrições).
- IA de Jogos: Implementar IA para jogos onde a IA precisa explorar possíveis movimentos e avaliar suas consequências.
Adicionei abaixo dois exemplos, um para BFS e outro para DFS. O grafo usado foi o da imagem abaixo:
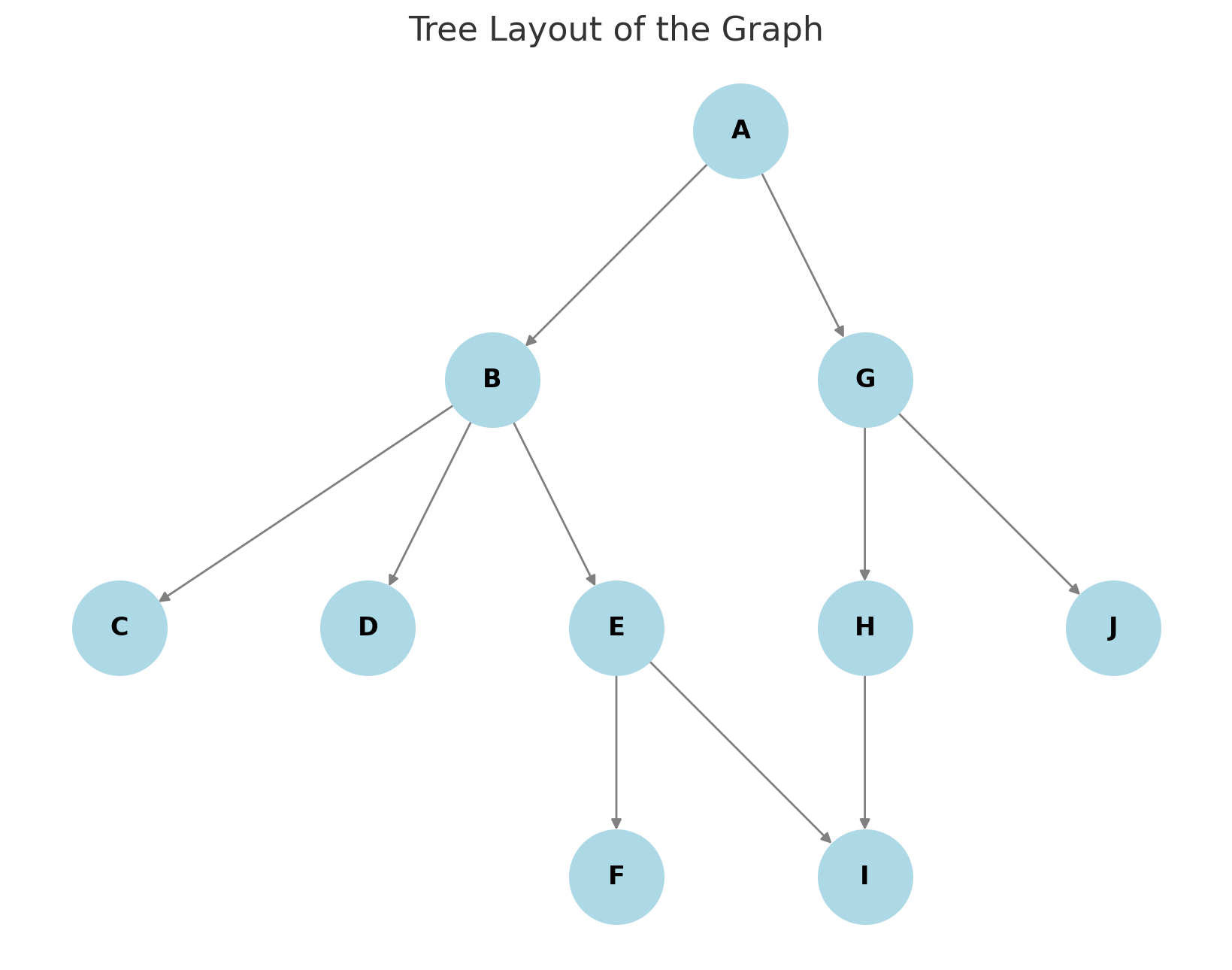
Este é o resultado de ambos, onde podemos notar a diferença:
bfs.py:
| |
Ordem de Visitação:
- Nível 0: [‘A’]
- Nível 1: [‘B’, ‘G’]
- Nível 2: [‘C’, ‘D’, ‘E’, ‘H’, ‘J’]
- Nível 3: [‘F’, ‘I’]
Ele visita todos os nós no nível atual antes de ir para o próximo nível.
dfs.py:
| |
Ordem de Visitação:
- ‘A’: Nó inicial, removido primeiro.
- ‘G’: De ‘A’, vizinhos são [‘B’, ‘G’]. Adicionado à pilha como [‘B’, ‘G’], então ‘G’ é removido em seguida (LIFO).
- ‘J’: De ‘G’, vizinhos são [‘H’, ‘J’]. Adicionado como [‘B’, ‘H’, ‘J’], ‘J’ removido.
- ‘H’: De ‘J’, nenhum novo vizinho. Pilha agora [‘B’, ‘H’], ‘H’ removido.
- ‘I’: De ‘H’, vizinho ‘I’ adicionado, removido em seguida.
- ‘B’: Pilha agora [‘B’], removido após a subárvore de ‘G’ ser esgotada.
- ‘E’: De ‘B’, vizinhos [‘C’, ‘D’, ‘E’]. Adicionado como [‘C’, ‘D’, ‘E’], ‘E’ removido.
- ‘F’: De ‘E’, vizinhos [‘F’, ‘I’]. ‘I’ já visitado, então ‘F’ adicionado e removido. Alvo encontrado, para.
Ele vai fundo no ramo de ‘G’ (‘G’ → ‘J’ → ‘H’ → ‘I’) antes de retroceder para ‘B’ e então ‘E’ → ‘F’.
Exemplo de BFS (Clique para Mostrar/Esconder)
| |
Exemplo de DFS (Clique para Mostrar/Esconder)
| |